Intro
The cache system is an elegant and essential part of computers, and it is so imperceptible that people seldom pay attention to it. I will implement a universal structure for a sound cache system in this post.
Types of cache
Usually, based on how it maps data, there are three types of cache systems.
- directly-mapped cache
- fully-associated cache
- set-associated cache
In brief, a directly-mapped cache always maps data into a certain block based on its address, which is extremely simple and fast. And a fully-associated cache maps to an arbitrary usable block, which lowers the possibility of conflicts. As a result, a directly-mapped cache has to replace blocks frequently since some data may scramble for the same block. On the other hand, a fully-associated cache should pay a great overhead for comparing all blocks whenever there is random access. Therefore, as the combination of the two aforementioned types, there is the set-associated cache. The cost of comparison is decreased by packing several blocks into a set and making it a FA cache. Moreover, the accessing efficiency is maintained by introducing more sets. Since this is not a post for the basics of cache systems, we will skip the detailed mechanism of each cache system.
Preparation
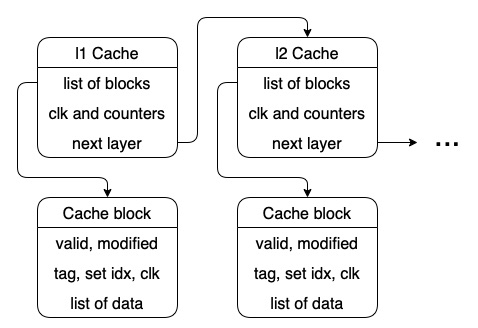
To implement those three types efficiently, defining one class and emulating all, we should focus on their common features. The conclusion is that a DM cache is an n-set 1-block SA cache and a FA cache is a 1-set m-block SA cache. Hence, rather than considering SA cache as the combination of DM cache and FA cache, it would be better to treat DM cache and FA cache as the special corner cases of SA cache. Furthermore, the main memory is necessary for the cache system. But implementing the main memory class will be predictably tedious work as well. Therefore, instead of implementing a special main memory, let’s just regard it as a 1-set 1-block cache in which the only block is valid at the time of initialization. Then with a clever way of identifying cache and memory, every part of our implementation can share the same interfaces.
Workflow
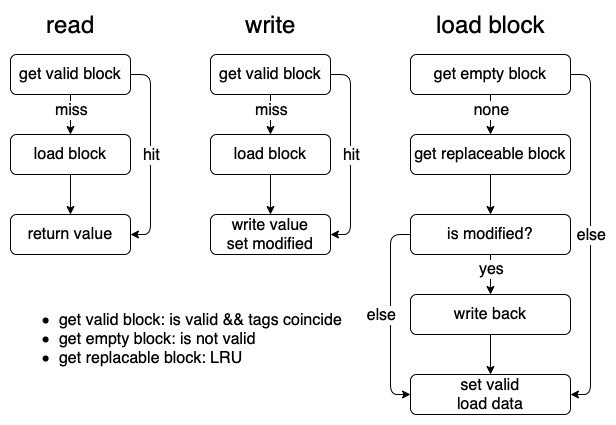
In this section, we are stepping closer to the actual implementation. Different from reading data, consistency should be carefully taken care of when writing. Since there are some modified values, the exact timing of reflecting it to the lower layer is crucial, and there are mainly two methods of reflecting modified data.
- write-through: write back immediately when modified
- write-allocate: write back when the block is about to be replaced
Besides these two, one optional strategy is write-through for the 1st modification and then write-allocate. In my implementation, write-allocate is adopted. As a result, the reading and writing flow could be described as follows, and the implementation is explicit and intuitive.
Cache class
The actual designs are divided into two parts, one for the overall cache system and another for the cache block that stores data. Convincing the upper layer that its next layer has the wanted data, we may universalize the structure with the design pattern of CoR. Once a cache miss happened at the upper layer, just calling data from the lower layer would be fine. Therefore, the upper layer shall never consider how the lower layer provides those data.