前情提要
什么是汇编语言?
自上而下来看,汇编语言属于高级语言被编译成机器语言代码前的最后一个阶段。在这个阶段中,高级语言的绝大多数抽象特性已被移除,如变量、循环、函数等,只保留了条件跳转以及使用统一命名的寄存器代替变量。也正因如此对于率先接触高级语言的学习者来说,汇编语言无论是从学习、书写还是使用等各个角度都不是十分符合“直觉”。
另一方面,倘若我们从程序语言发展顺序来看的话,汇编则是提供了初等的抽象特性。计算机诞生之初,编程人员曾在纸带上通过打孔的方式表示0和1,从而实现编程。此等做法难以实现大规模书写,同时极易出错,不便于后期调试。为此汇编语言应运而生,将机器语言的指令以一一对应的方式重新命名,直接书写英文单词,将转换的工作交给专门的机器来做。这一机器则是本文的重点:“汇编器”(assembler)。
在实际步入汇编的世界之前我们也应需明确一下汇编语言的局限性。汇编语言建立于ISA(指令集架构)之上,因此不同的ISA就对应了不同的汇编语言,常见的架构x86、POWER PC、ARM、RISC-V等。也就是说不同于C/C++、python等语言,汇编语言并非是某一语言的名字,而是一类语言的统称。所谓学习汇编语言,也就是基于某一ISA熟悉汇编书写的思路罢了。脱胎于本人在大学实验课中的项目,本文将使用较新的RISC-V架构的汇编语言展开。
汇编语言初见
按照一般学习编程语言的惯例,我们本应使用汇编实现一段“Hello world”。但基于system call实现的“Hello world”体现不出汇编的特色,基于uart通信逐一输出“Hello world”字符的方式又有些过于偏向于硬件。所以在此我们用一段算斐波那契数的程序展示一下汇编层级的条件分支、函数调用等概念。
这是一段用C书写的fib.c程序
#include <stdio.h>
int fib(int n) {
return (n < 3) ? 1 : fib(n - 1) + fib(n - 2);
}
int main() {
printf("fib(%d) = %d\n", 10, fib(10));
return 0;
}
使用简单的递归即可实现。以下则是个人书写的等价汇编代码。
.globl main
.data
const:
.word 10
.text
fib: # a0 = n
addi sp, sp, -12
sw ra, 0(sp)
li t0, 3
blt a0, t0, tb
sw a0, 4(sp) # save current n
addi a0, a0, -1 # a0 = n - 1
call fib # fib (n - 1)
sw a0, 8(sp) # save fib (n - 1)
lw a0, 4(sp)
addi a0, a0, -2 # a0 = n - 2
call fib # fib (n - 2)
lw a1, 8(sp)
add a0, a0, a1
j final
tb:
addi a0, zero, 1
final:
lw ra, 0(sp)
addi sp, sp, 12
ret
main:
la t0, const
lw a0, 0(const)
call fib # call fib(a0)
ebreak
RISC-V的汇编语言中,以label:的方式声明标签,这样的标签可以通过跳转等命令直接使用,如示例中的blt a0, t0, tb、call fib、j final等。同时汇编语言代码中程序(code)和数据(data)同时存在,并以.text和.data两种指令标签区分,即跟在text后面的内容被视为代码,跟在data后面的内容视为数据。此外的内容皆为RISC-V架构下的一些实际指令了,均为一些英文的缩写,参照下表即可略知一二。
| 汇编指令 | 实义 |
|---|---|
addi rd, rs1, imm |
add immediate value |
blt rs1, rs2, tag |
branch to tag if rs1 < rs2 |
sw rs2, imm(rs1) |
store word of |
call tag |
call a subroutine |
j tag |
jump to tag without any condition |
ret |
return from current subroutine |
li rd, imm |
load immediate value to rd |
la rd, tag |
load the address of tag to rd |
汇编语言的翻译
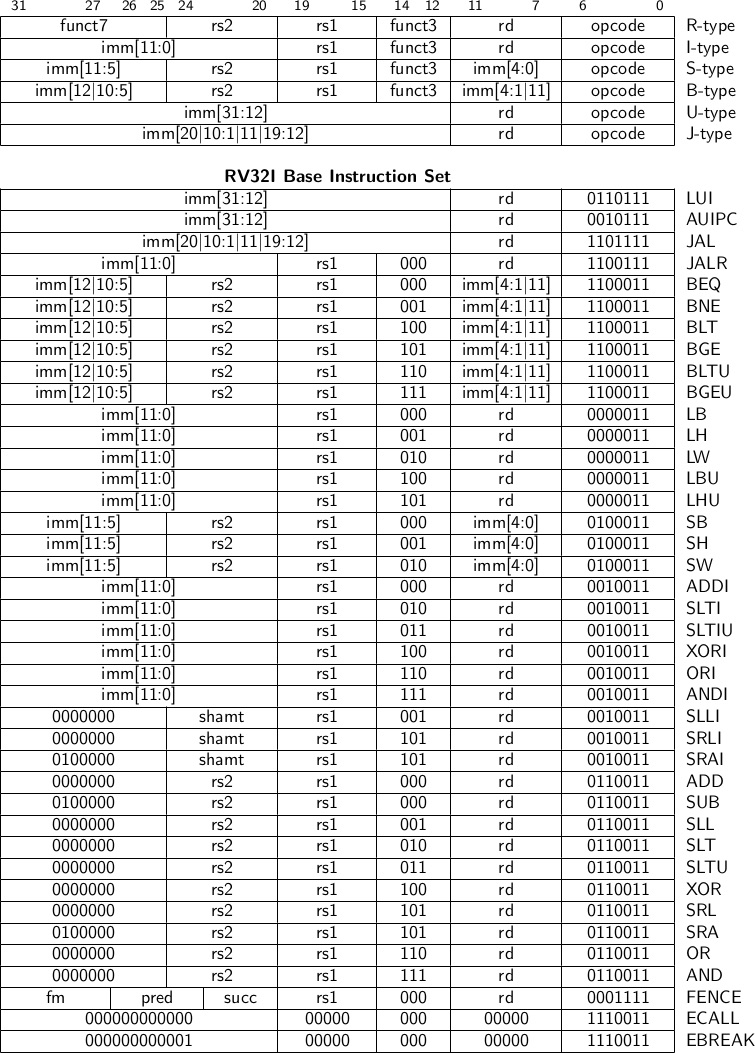
在RISC-V的ISA中,所有的指令都会被划归为以上的6大类。绝大部分的指令直接就可以被翻译成机器语言,如R/I/S/U-type,比如addi a0, a1, 1,其表意为a0 = a1 + 1。其中a0是第10个通用寄存器,a1是第11个通用寄存器,那么上述语句即可直接翻译为000000000001 01011 000 01010 0010011。但相反,属于B-type的branch系列和属于J-type的jal则无法直接翻译。具体原因和解决方案我们将在后文详述。
汇编器的难点
接下来让我们步入正题:正确翻译汇编语言到机器语言代码。在实际落笔前,我们首先应明确这个任务的难点。鉴于网络上鲜有汇编器的教程文章,开源代码本人也没能潜心阅读,以下的总结皆为个人经验的汇总。在阅读时建议与第三节的构建思路对应着看。
标签定义次序不定
汇编通过标签的有无条件跳转实现了程序流的控制,但正因如此当我们顺序读取汇编代码时就会遇到标签定义顺序的问题。即先遇到了使用该标签的跳转语句,却不知道该标签的具体位置,从而导致无法翻译的问题。举例来说,在文首的斐波那契示例代码中我们有blt a0, t0, tb一句,但这个branch语句中使用了在后续才定义的tb标签,那么顺序读取汇编代码到这时我们并不知道tb具体在哪里,也就无法将其实际地址填入B-type的imm域中。J-type的jal也是会面临同样的问题。因此妥善解决这个这个问题将是汇编器的第一大考验。
伪指令的处理
仔细阅读斐波那契示例代码可见,如addi、blt等命令出现在了1.3节的表中,但la、li以及j等命令却没有。其原因是la、li以及j等命令并非RISC-V ISA中的标准命令,而属于是“伪指令”。这样的指令在翻译过程中由汇编器自动转换为语义相同的标准指令,其主要目的是使语义表达更加清晰、简洁。
对于绝大多数的伪指令来说都是与标准指令一一对应的,但不排除有一对多的情况如li、call等。常见伪指令对应关系如下。
| 伪指令 | 语义 | 实际指令 |
|---|---|---|
nop |
no operation | addi zero, zero, 0 |
li rd, imm |
load immediate | lui rd, %hi(imm) |
addi rd, rd, %lo(imm) |
||
la rd, tag |
load address | auipc rd, %hi(&tag - pc) |
addi rd, rd, %lo(&tag - pc) |
||
mv rd, rs1 |
copy register | addi rd, rs1, 0 |
j tag |
jump | jal zero, tag |
jal tag |
jump and link | jal ra, tag |
call tag |
call a subroutine | auipc t0, %hi(&tag - pc) |
jalr ra, %lo(&tag - pc)(t0) |
由于伪指令展开有可能打乱指令长度,因此妥善处理伪指令将是第二大考验。
语义优化
最后,在程序世界里我们永远离不开优化问题,在编译器里也是如此。比如对于一对多的伪指令,我们就可以尝试削减不必要的部分,从而实现指令的精简。
比如对于li伪指令,一般被展开为lui与addi两条,这样一来不论多长的数字都可以被填入指定寄存器中。但更多情况下我们往往只会代入很小的数字,小到12bit都绰绰有余,此时负责上位20bit的lui命令就会变为冗余。la和call指令也是同理。
相反,有一些问题则是不得不优化的,比如在我个人开发过程中就遇到了branch系列指令imm域不够长的问题。根据B-type指令的定义,立即数域只有12bit,省略掉最低位的1bit,最多可以表示13bit的有符号数,即-4096~4095。也就是说分支目标在这个范围内时可以正确跳转,当超过这个范围时就会无法表示全尽,跳转错误。尽管这个错误可以由汇编器发现,随后交给人工调整汇编代码块的位置,但倘若汇编器为toolchain的一环,自动接在编译器后调用的话则需要汇编器自行处理。在语义转换上我们可以采取如下方式,将beq rs1, rs2, tag改写为
bne rs1, rs2, new-tag
j tag
new-tag:
...
但仍需考虑由于指令长变化导致的实际地址变动的问题,因此语义优化可以认为是汇编器的又一大考验。
构建思路
$O(n)$至上
在本小节中我们主要考虑基本汇编代码的处理,不掺杂伪指令,着重解决基本汇编代码的翻译。
传统思路
有如2.1中所述,顺次翻译汇编时会遇到标签定义次序的问题。为此最容易想到的方式就是使用dict等数据结构统一收集标签地址对,遇到未收集的数据时以当前指令为出发点向下探索,补充上该信息后再顺次执行。可以想见这种处理方式将会达到$o(n^2)$的时间复杂度,在处理大程序时会极其耗时,而且难以应对后续问题。在此我们便不再多议。
分阶段处理
尽管汇编器仅仅是编译流程中的很小的一环,但为了整体的处理效率,$O(n)$仍应该是我们努力的目标。为此,我们可以将汇编器翻译的步骤分开,不再一遍读取一边翻译,而是将整个过程分为两部分。在第一次遍历时只对汇编指令做一步预处理(将字符串打散成tuple等),同时收集所有标签的地址信息。由于我们不考虑一对多的伪指令,所以每遇到一条指令时机械化地对地址counter加4(32bit->4byte)即可。这样一来通过一次遍历所需信息完备,在第二次重新遍历时就不会遇到标签未定义的问题了。整体只做了两次遍历,所以时间复杂度仍然为$O(n)$。大体代码结构如下
-
decoder.py:主要负责源代码解析,使用re.match将字符串打散为tuple。import re decoder = { # tag 'TAG': re.compile(r'(\S+):'), # directive 'DIREC-DATA': re.compile(r'\.(\S+?)\s+(.+)'), 'DIREC-PLAIN': re.compile(r'\.(\S+)'), # pc rd, imm 'LUI': re.compile(r'(lui)\s+(\S+),\s+(\d+)'), 'AUIPC': re.compile(r'(auipc)\s+(\S+),\s+(\d+)'), # jal rd, tag 'JAL': re.compile(r'(jal)\s+(\S+),\s+(\S+)'), # jalr rd, offset(rs1) 'JALR': re.compile(r'(jalr)\s+(\S+),\s+(-?\d+)\((\S+)\)'), # branch rs1, rs2, tag 'BEQ': re.compile(r'(beq)\s+(\S+),\s+(\S+),\s+(\S+)'), ... # load rd, offset(rs1) 'LW': re.compile(r'(lw)\s+(\S+),\s+(-?\d+)\((\S+)\)'), # store rs2, offset(rs1) 'SW': re.compile(r'(sw)\s+(\S+),\s+(-?\d+)\((\S+)\)'), # arith_i rd, rs1, imm 'ADDI': re.compile(r'(addi)\s+(\S+),\s+(\S+),\s+(-?\d+)'), ... # arith rd, rs1, rs2 'ADD': re.compile(r'(add)\s+(\S+),\s+(\S+),\s+(\S+)'), ... } -
encoder.py:主要负责实际机器代码生成,使用dict保存指令类别和处理函数的对应关系。... # branch imm[12,10:5] rs2 rs1 funct3 imm[4:1,11] 1100011 def branch(instr: tuple, addr: int, tags: dict) -> int: name = instr[0] rs1 = reg2idx(instr[1]) rs2 = reg2idx(instr[2]) imm = tag2offset(instr[3], tags, addr) mc = 0b1100011 mc |= ((imm & 0x00000800) >> 11) << 7 # 11 mc |= ((imm & 0x0000001E) >> 1) << 8 # 4:1 if name == 'BEQ': mc |= 0b000 << 12 elif name == 'BNE': mc |= 0b001 << 12 elif name == 'BLT': mc |= 0b100 << 12 elif name == 'BGE': mc |= 0b101 << 12 else: # not suppose to be here raise RuntimeError(f'unrecognizable branch type : {name}') mc |= (rs1 & 0x1F) << 15 mc |= (rs2 & 0x1F) << 20 mc |= ((imm & 0x000007E0) >> 5) << 25 # 10:5 mc |= ((imm & 0x00001000) >> 12) << 31 # 12 return mc ... encoder = { # pc 'LUI': lui, 'AUIPC': auipc, # jal 'JAL': jal, # jalr 'JALR': jalr, # branch 'BEQ': branch, ... # load 'LW': load, # store 'SW': store, # arith_i 'ADDI': arith_i, ... # arith 'ADD': arith, ... } -
asm.py:主体文件,负责统筹上述的decoder.py和encoder.py
上述代码结构中的绝大部分都会沿用在后续设计中。完整代码可参见个人项目(commit 28f0b0a)。
多携带一些信息
在解决完基本翻译流程后,我们的汇编器就已初具雏形。因为上述代码结构也具备一定的扩展能力,接下来我们便基于这个设计使其具有处理伪指令的能力。细细想来,伪指令处理与基本指令的翻译基本无差,不外乎就是汇编器多做了一步转化,所以对于一对一的伪指令,我们就可以直接encoder.py中补充上对应的处理函数即可。
def pseudo_nop(instr: tuple, addr: int, tags: dict):
return arith_i(('ADDI', 'zero', 'zero', '0'), addr, tags)
对于一对多的伪指令,我们虽然可以在asm.load的阶段分情况处理,比如遇到li命令就加8等等,但此种做法实属不美观。为此我们则可以拓展decoder.py所携带的信息,提前预设好每个指令的预期长度,在给codeCounter做加法时直接利用这个信息即可。同时为了方便处理,encoder.py中的各个返回值可以包装成list。
-
decoder.py:在解码字典中多携带一个预期长度的信息,方便外层数长度。decoder = { ... # pseudo 'PSEUDO-NOP': (re.compile(r'(nop)'), 1), 'PSEUDO-LI': (re.compile(r'(li)\s+(\S+),\s*(-?\S+)'), 2), 'PSEUDO-LA': (re.compile(r'(la)\s+(\S+),\s*(\S+)'), 2), 'PSEUDO-NOT': (re.compile(r'(not)\s+(\S+),\s*(\S+)'), 1), 'PSEUDO-MV': (re.compile(r'(mv)\s+(\S+),\s*(\S+)'), 1), 'PSEUDO-J': (re.compile(r'(j)\s+(\S+)'), 1), 'PSEUDO-JAL': (re.compile(r'(jal)\s+(\S+)'), 1), 'PSEUDO-JALR': (re.compile(r'(jalr)\s+(\S+)'), 1), 'PSEUDO-RET': (re.compile(r'(ret)'), 1), ... } -
encoder.py:对一对多的伪指令做直接展开,返回对应的机器代码列表。def pseudo_li(instr: tuple, addr: int, tags: dict) -> list: _, rd, imm = instr hi, lo = getHiLo(imm2int(imm)) return lui(('LUI', rd, str(hi)), addr, tags) + \ arith_i(('ADDI', rd, rd, str(lo)), addr + 4, tags)
这样一来一对多的伪指令也就可以和其他指令一样处理了。完整代码可参见个人项目(commit 5b4ca70)。
多加一些处理阶段
理论上到此为止这个阶段的汇编器已经可以处理90%以上的汇编代码了。除了li、call等指令的优化,我们可以在encoder.py的各个函数中加入一些检查的内容,把立即数域不够的情况反馈给使用者。但为了开发一款强力的汇编器,上述结构亟待改良。
分析指令特征,细化处理层次
经分析可发现,li指令的优化早在解码时就可进行操作,毕竟立即数的代入不依存于其他的信息。此外,branch系列和call指令的优化则可在第一次遍历解码完毕时尽心操作。我们给各个指令的预设长度全都指定为可想见的最大值,比如li、call均为2之类的,如此一来预设的长度总和一定会小于实际的长度总和。那么,如果branch系列和call指令可以在预设的长度(较长的跨度)下进行优化,则其必可以在实际的长度下进行优化(代码长度整体会缩减)。为此我们可以在现有的两次遍历中增加一些额外的层:优化处理层(optimize)和最终确定层(finalize),优化处理层利用由预设长度(assumed length)构建的地址表识别可优化命令,并一边最终确定其实际长度(actual length),一边汇总实际长度信息、构建最终的地址表。大致流程如下图所示。
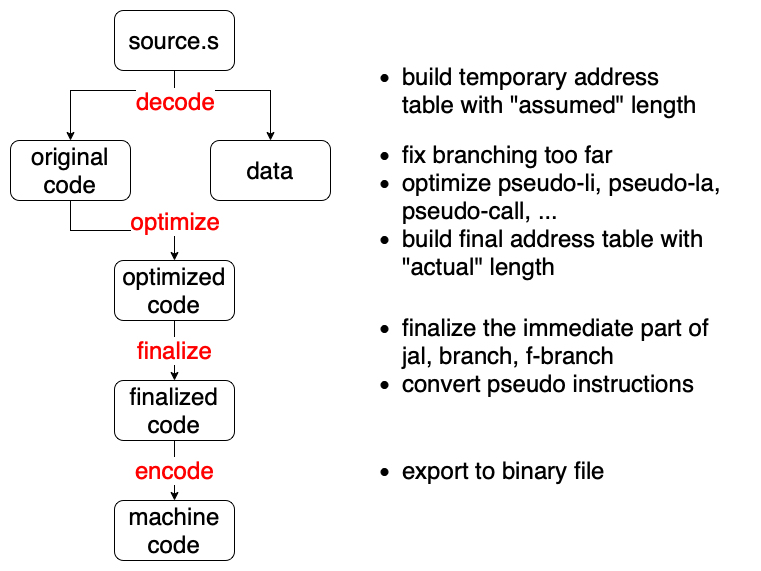
其中一对一的伪指令的处理时机比较灵活,既可以放在优化处理层,也可以放在最终确定层实现。我个人选择了延迟处理,尽可能地将转化都放在了最终确定层。
高度结构化
由上述全新设计的结构可见,在整个处理流程中我们使用了比前两版多得多的中间信息。可以想见简单的tuple已经无法满足使用需求了,高度的结构化必然是大势所趋。在此我采用了设计模式(design pattern)中的工厂模式(Factory Method)和责任链模式(Chain of Responsibility),让实际操作逐层向下传递,上一层建立在下一层的抽象上进行操作。
其中最小的结构我们称其为Code,与前两版中encoder.py的工作类似,负责每一个指令的实际优化/转换等操作。它会记录每条指令的各种信息,以及具有各个阶段对应的函数。所有指令继承Code类,具体化各个信息。
Code:
- rd, rs1, rs2, tag, ...
- assumedLength, actualLength
- optimize()
- finalize()
- encode()
- ...
然后,Code的外层由Block包裹,可以理解为代码块(虽然绝大部分的代码块都是一个指令)。其职责一部分与前两版的decoder.py相同,只不过不再返回tuple,而是返回一个包装好的Block实例。此外,Block还负责其包含的Code的统筹工作,使得最外层的ASM类不需要直接接触Code而是仅与Block打交道即可。
Block:
- originalCode -> Code
- processedCodeList -> List[Code]
- lineno, address
- optimize()
- finalize()
- encode()
- decode() -> Factory Method
- ...
如此一来,最外层的ASM类只需要在每一次遍历时访问Block类中对应的方法即可。例如下图。
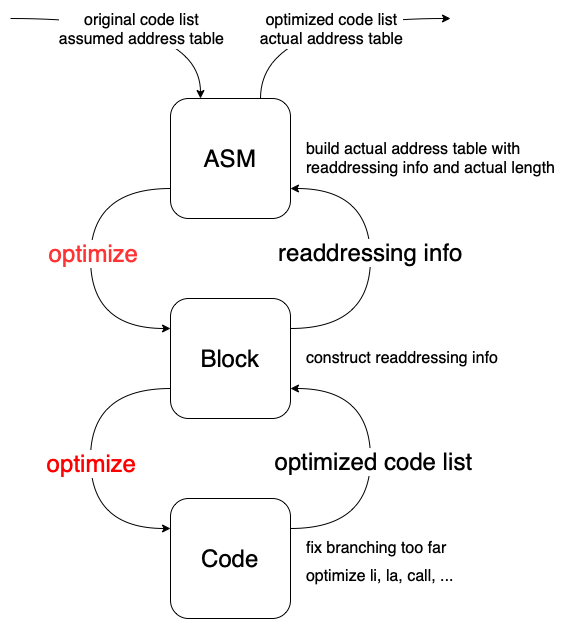
同时基于类所能携带的大量信息,我们也能够输出更丰富的debug内容,这一部分可充分自由发挥。完整代码参见学校课题项目或者个人简化项目。
声明
本文属于对2021年A学期大学实验课小组项目的部分总结,文章中提及的参考代码包含了部分小组定制的内容,请读者参考大体结构即可。